Rows: 2530 Columns: 10
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (7): company_manufacturer, company_location, country_of_bean_origin, spe...
dbl (3): ref, review_date, rating
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
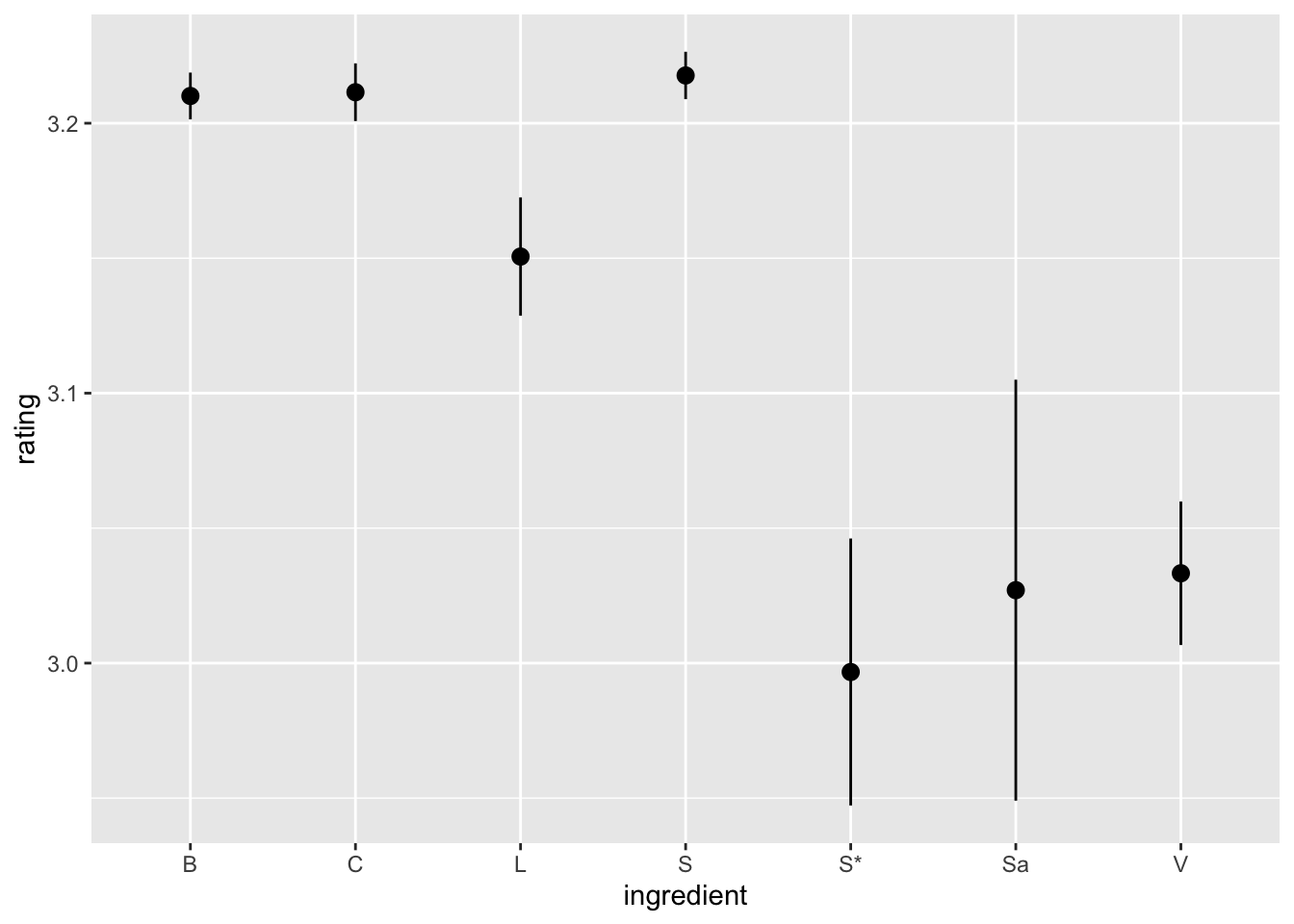
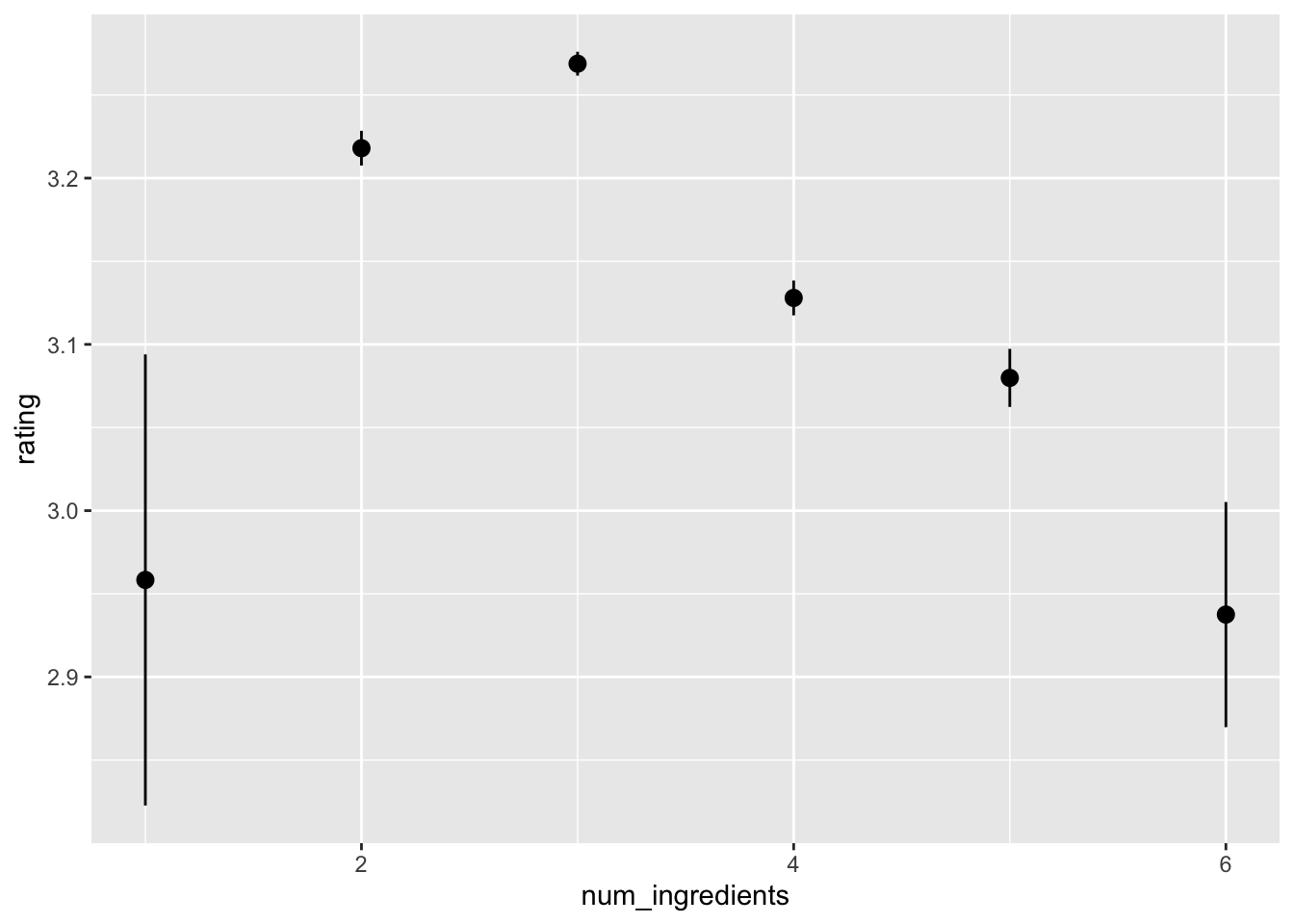
Make data tidy
First make a wide dataset
chocolate_wide <- chocolate %>%# separating ingredients and characteristics out widerseparate_wider_delim(cols =c(ingredients, most_memorable_characteristics),delim =",",names_sep ="_",too_few ="align_start" ) %>%# repair first ingredient columnseparate_wider_delim(cols = ingredients_1,delim ="-",names =c("num_ingredients", "ingredients_1") ) %>%# make num_ingredients numericmutate(num_ingredients =as.numeric(num_ingredients))
Then we can pivot_wider()… for instance the ingredients columns