Combining Functions & Purrr for simulations
A simple example
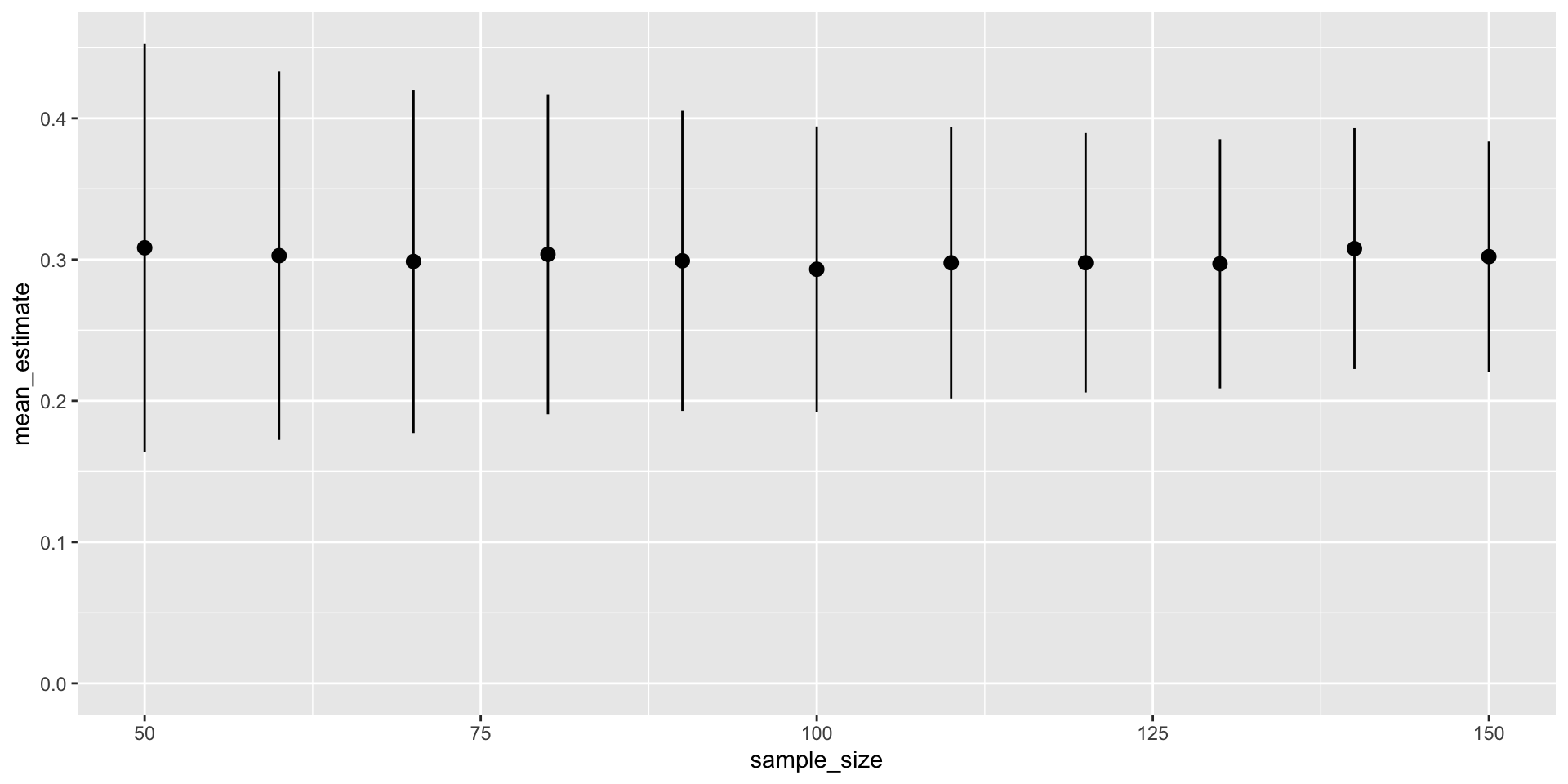
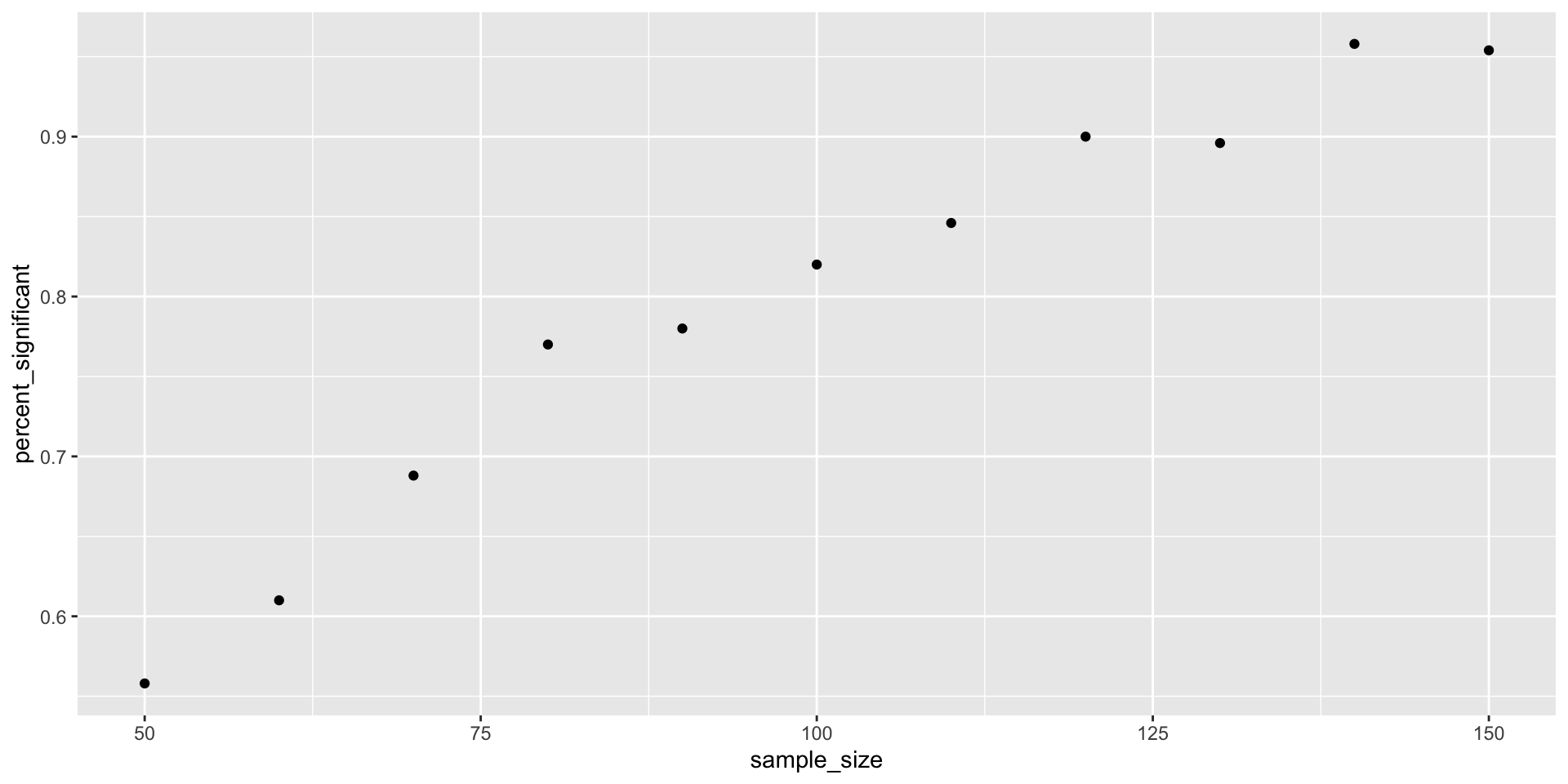
Let’s say we want to calculate the power to detect a correlation of .31
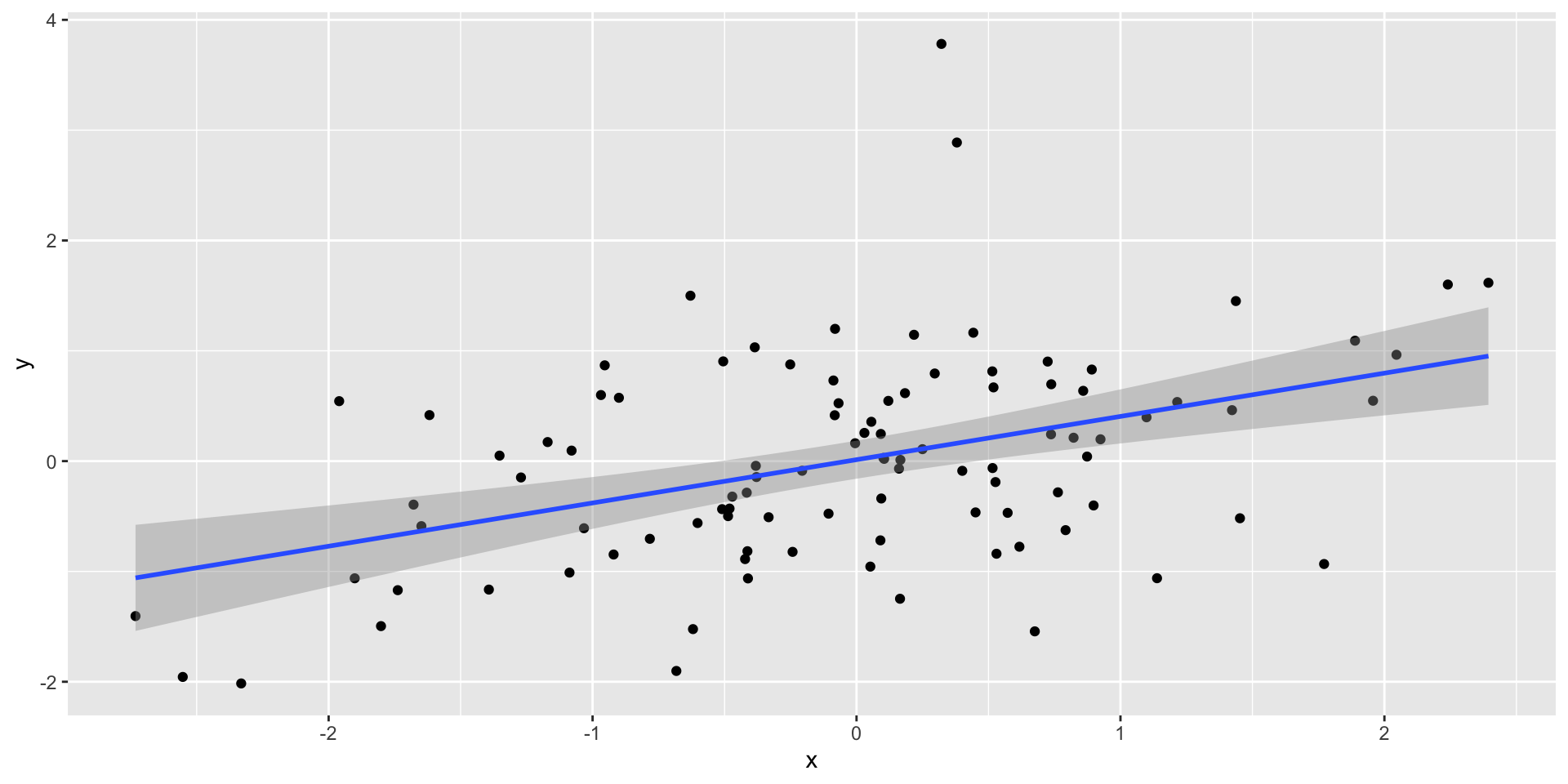
Let’s try and make it better :)
sim_outcome %>%
unnest(tidy_model) %>%
filter(term == "measure_1") %>%
group_by(sample_size) %>%
summarise(across(c(estimate, std.error), c("mean" = mean), .names = "{.fn}_{.col}")) %>%
ggplot(aes(sample_size, mean_estimate, ymin = mean_estimate - mean_std.error, ymax = mean_estimate + mean_std.error)) +
geom_pointrange() +
expand_limits(y = c(0, 0.35))